

Imagine that you’ve just started to work as an HR specialist for a big healthcare company. Your boss walks over to give you your first big assignment.
She tells you that your company needs to hire its very first data scientist, but they’re not sure how to find one. The HR department is used to hiring doctors, not data people. They’re not sure what skills are prevalent in the market, where the talent is located, what attracts them, or even how these job descriptions are written.
To fix this, she asks you go on a scavenger hunt deep into the Internet to collect job descriptions for data scientist positions. After you have them all collected, you’re supposed to read them all and make a report on the trends you notice.
At first, you’re thinking, “okay, cool, sounds easy enough.” But then you ask her just how many job descriptions she wants you to read. She says, “you know, around 7,000 should do the trick.”
Your jaw drops.
If each job description takes up a page, then that’s like reading 7 volumes of War and Peace.
Before you start reconsidering your career choices, you may want to talk to Atlanta-based student David Antzelevich. Utilizing what he’s learned in Thinkful’s Data Science program, he used machine learning and natural language processing to read, interpret, and analyze them for you.
To get your analysis done, David first had to prepare the text for a computer to read
Humans and computers read differently. We can easily see that “BA,” “BS,” “bachelor” and “bachelors” are all referring to a similar type of degree. Computers, on the other hand, would read these all as different terms. Before a computer could read the text, David had to clean it up a bit.
To do this, David used Regular Expressions to standardize different spellings and produce a nice, clean text ready for computer processing.
After he finished tidying up, David built an unsupervised learning model to classify sentences into different categories (like information about the company, descriptions of the ideal candidate, and descriptions of roles and responsibilities, etc.).
With a clean, categorized text, David could now save you endless months of frustration with natural language processing
To do this, David used the NLTK word2vec algorithm. This algorithm employs dictionaries and vectors to identify similar words. For example, he could plug in one type of data science technology and quickly find all the other kinds of technologies mentioned in the text.
In fact, David did just that. With word2vec, David identified and compared the top technologies mentioned in data science job descriptions. His analysis shows that Python, r, and sql are most prevalent.

Next, David identified which industries are most in need of data scientists. our industry—Healthcare—takes fourth place, behind Marketing, Consulting, and Finance.

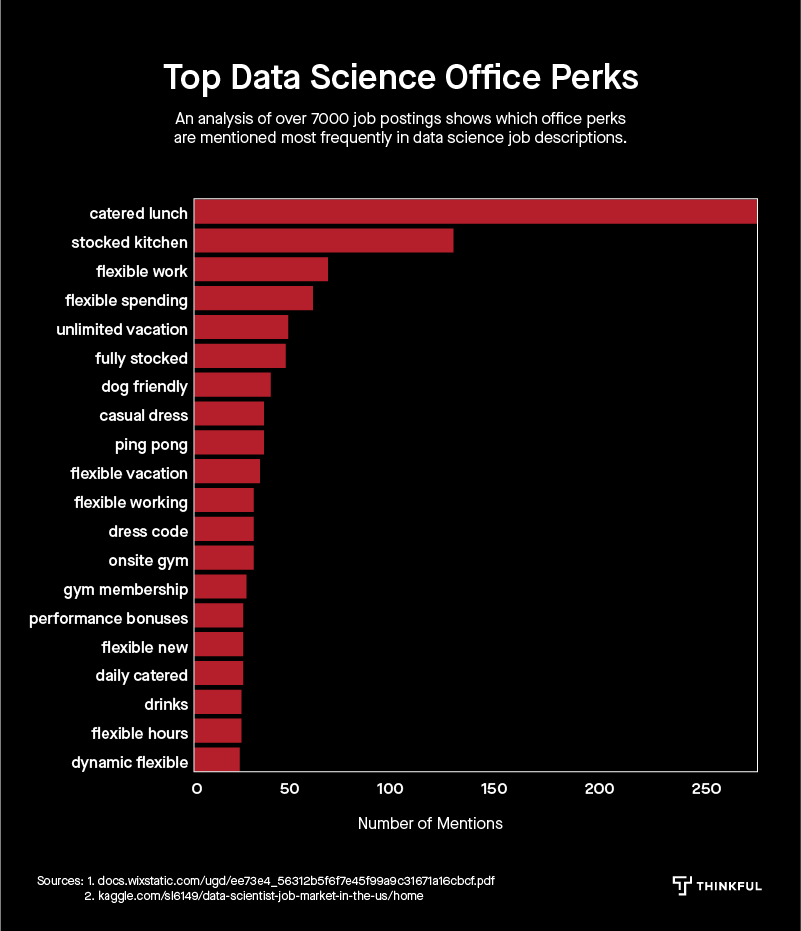
When your boss asks what sort of perks will attract the best data scientists, you can point her to David’s next chart. Clearly, it’s all about the food!
When you’re trying to describe the ideal candidate, you can get ideas from David’s chart of the top personality attributes people look for when hiring data scientists.

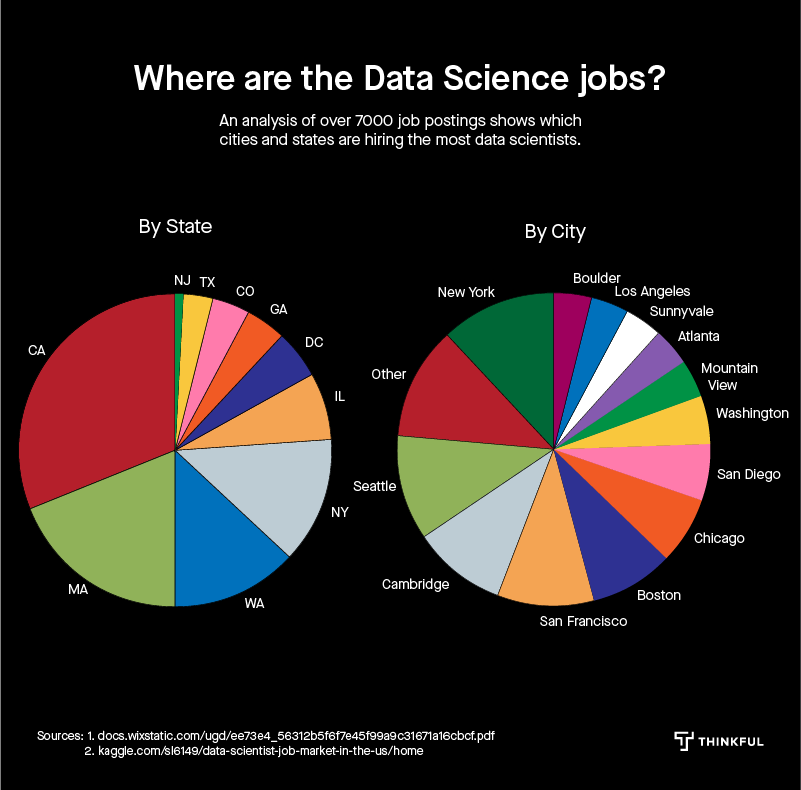
Finally, when your boss asks which regions hire the most data scientists, you can point her to David’s last chart.
Share this Story. Help a Job Candidate.
On behalf of all the current and aspiring data scientists at Thinkful, we’d love for you to share this story to help people better understand the data science job market.
If you’d like to cite this story on your digital publication or blog, please make sure to mention that this project was conducted by David Antzelevich, a student in Thinkful’s data science bootcamp.
If you’d like to chat with David about his analysis, or any of Thinkful’s data science experts, please email Adam Levenson.
Launch Your Data Science Career
An online data science course aimed at helping you launch a career. One-on-one mentorship, professional guidance, and a robust community network are on hand to help you succeed in Data Science.