More and more, data science is finding a way into our businesses, our communities, and in some cases, our lives.
But just what exactly is data science?
More and more, data science is finding a way into our businesses, our communities, and in some cases, our lives.
But just what exactly is data science?
More and more, data science is finding a way into our businesses, our communities, and in some cases, our lives.
But just what exactly is data science?
It's certainly something that seems to be on people's minds lately. Everyone is talking about it, a lot are claiming to do it, and increasingly, more people are hiring for it.
But what is it?
Data science, in its most basic terms, can be defined as obtaining insights and information, really anything of value, out of data. Like any new field, it's often tempting but counterproductive to try to put concrete bounds on its definition. This is data science. This is not. In reality, data science is evolving so fast and has already shown such enormous range of possibility that a wider definition is essential to understanding it.
And while it's hard to pin down a specific definition, it's quite easy to see and feel its impact. Data science, when applied to different fields can lead to incredible new insights. And the folks that are using it are already reaping the benefits…


It’s hard to imagine a world before data.
It has become ubiquitous, even more so for people who work in tech. We've gone so far as to personify data in everyday conversation. We ask what it means, what it says. But do we even know what it is?
What makes something count as data? Is a handwritten ledger from the year 1500 considered data? Is a book sitting on a store shelf data? Are we all just data?
In the context of data science, the only form of data that matters is digital data.
Digital data is information that is not easily interpreted by an individual but instead relies on machines to interpret, process, and alter it. The words you are reading on your computer screen are an example of this. These digital letters are actually a systematic collection of ones and zeros that encodes to pixels in various hues and at a specific density.
In recent years, digital information has gotten so pervasive and essential that we've almost become unwilling to handle anything that isn't in a digital form. Go ask a data scientist to work on something that isn't digitized. Hand them a table scrawled on a wrinkly piece of paper. Or, to better replicate the scale of what we're going to talk about, entire libraries of thick books, overflowing with tables of information. Stack them on their desk (if you can) and they'd probably run away and never come back. It is because the digital elements of information have become essential. We cannot do modern work without them.
It's hard to find another moment in human history where there was an innovation that made all previous stored information invalid.
If you really want a sense of how big this moment is in the context of what we're here to talk about, data science, just open any newspaper over the past 10 years. Inside, you will find countless stories of individuals, companies, and in some cases countries racing to digitize any and all information. From books to health records to government services, it's becoming increasingly challenging to find corners of society not impacted by the digital revolution.
It's incredible to think that while it may seem hyperbolic, it's hard to find another moment in human history where there was an innovation that made all previous stored information invalid. Even after the introduction of the printing press, handwritten works were still just as valid as a resource. But now, literally every piece of information that we want to endure has to be translated into a new form.
Of course, the digitization of data isn't the whole story. It was simply the first chapter in the origins of data science. To get to the point where the digital world would become intertwined with almost every person's life, data had to grow. It had to get big. Welcome to Big Data.
In 1964, Supreme Court Justice Potter Smith famously said “I know it when I see it” when ruling whether or not a film banned by the state of Ohio was pornographic. This same saying can be applied to the concept big data. There isn't a steadfast definition and while you can't technically see it, an experienced data scientist can easily pick out what is and what is not big data. For example, all of the photos you have on your phone is not big data. However, all of the photos uploaded to Facebook everyday… now we're talking.
Like any major milestone in this story, Big Data didn't happen overnight. There was a road to get to this moment with a few important stops along the way, and it's a road on which we're probably still nowhere near the end. To get to the data driven world we have today, we needed scale, speed, and ubiquity.
To anyone growing up in this era, it may seem strange that modern data started with a punch card. Measuring 7.34 inches wide by 3.25 inches high and approximately .07 inches thick, a punch card was a piece of paper or cardstock containing holes in specific locations that corresponded to specific meanings. In 1890, they were introduced by Herman Hollereith (who would later build IBM) as a way to modernize the system for conducting the census. Instead of relying on individuals to tally up for example, how many Americans worked in agriculture, a machine could be used to count the number of cards that had holes in a specific location that would only appear on the census cards of citizens that worked in that field.

The problems with this are obvious - it's manual, limited, and not to mention fragile. Coding up data and programs through a series of holes in a piece of paper can only scale so far, but it's incredibly useful to remember it for two reasons: First, it is a great visual to keep in mind for data and second, it was revolutionary for its day because the existence of data, any data, allowed for faster and more accurate computation. It's sort of like the first time you were allowed to use a calculator on a test. For certain problems, even the most basic computation makes a world of difference.
The punch card remained the primary form of data storage for over half a century. It wasn't until the early 1980s that a new technology called magnetic storage rolled around. It manifested in different forms including large data rolls but the most notable example was the consumer friendly floppy disk. The first floppy disks were 8 inches and contained 256,256 bytes of data, about 2000 punch cards worth (and yes, it was sold in part as holding the same amount of data as a box of 2000 punch cards). This was a more scalable and stable form of data, but still insufficient for the amount of data we generate today.
With optical discs (like the CD's that still exist in some electronic stores or make frequent mobiles in children's crafting classes) we again add another layer of density. The larger advancement from a computational perspective is the magnetic hard drive, a laser encoded drive initially capable of holding gigabytes — now terabytes. We've gone through decades of innovation very quickly, but to put it in scale, one terabyte (a reasonable amount of storage for a modern hard drive) would be equivalent to 4,000,000 boxes of the earlier form punch card data. To date, we've generated about 2.7 zetabytes of data as a society. If we put that volume of data into a historical data format, say the conveniently named 8 inch floppy disk and stacked them end to end it would go from earth to the sun 5,300 times.
That said, it's not like there's one hard drive holding all of this data. The most recent big innovation has been The Cloud. The cloud, at least from a storage perspective, is data that is distributed across many different hard drives. A single modern hard drive isn't efficient enough to hold all the data even a small tech company generates. Therefore, what companies like Amazon and Dropbox have done is build a network of hard drives, and get them better at talking to each other and understanding what data is where. This allows for massive scaling because it's usually easy to add another drive to the system.
Speed, the second prong of the big data revolution involves how, and how fast we can move around and compute with data. Advancements in speed follow a similar timeline to storage, and like storage, are the result of continuous innovation around the size and power of computers. You may not realize this, but the device you are reading this article on is significantly more powerful than initial computers despite being just a fraction of their size (the first computers were the size of entire rooms).
The combination of increased speed and storage capabilities incidentally led to the final component of the big data story: changes in how we generate and collect data. It's safe to say that if computers had remained massive room-sized calculators, we may never have seen data on the scale we see today. Remember, people initially thought that the average person would never actually need a computer, let alone one in their pocket. They were for labs and highly intensive computation. There would have been little reason for the amount of data we have now — and certainly no method to generate it. The most important event on the path to big data is not in fact the infrastructure to handle that data, but the ubiquity of the devices that generate it.
As we use data to inform more and more about what we do in our lives, we find ourselves writing more and more data about what we are doing. Almost everything we use that has any form of cellular or internet connection is now being used primarily to receive and, just as importantly, write data. Anything that can be done on any of these devices can also be logged in a database somewhere far away. That means every app on your phone, every website you visit, anything that engages with the digital world can leave behind a trail of data.
It's gotten so easy to write data, and so cheap to store it, that sometimes companies don't even know what value they can get from that data. They just think that at some point they may be able to do something and so it's better to save it than not. And so the data is everywhere. About everything. Billions of devices. All over the world. Every second. Of every day.
This is how you get to zetabytes. This is how you get to big data.
But what can you do with it?
The short answer to what you can do with the billions upon billions upon of data points being collected is the same as the answer to the first question we asked:
Data science.
With so many different ways to get value from data, categorization will help make the picture a little clearer.
Let's say you're generating data about your business. Like, a lot of data. More data than you could ever open in a single spreadsheet and if you did, you'd spend hours scrolling through it without making so much as a dent. But the data is there. It exists and that means there's something valuable in it. But what does it mean? What's going on? What can you learn? Most importantly, how can you use it to make your business better?
Data analysis, the first subcategory of data science, is all about asking these types of questions.
With the scale of modern data, finding answers requires special tools, like SQL or Python or R. They allow data analysts to aggregate and manipulate data to the point where they can present meaningful conclusions in a way that's easy for an audience to understand.
Though it is true of all aspects of data science, data analysis in particular is dependent on context. You have to understand how data came to be and what the goals of the underlying business or process are in order to do good analytic work. The ripples of that context are part of why almost no two data science roles are exactly alike. You couldn't go off and try to understand why users were leaving a social media platform if you didn’t understand how that platform worked.
It takes years of experience and expertise to really know what questions to ask, how to ask them, and what tools you’ll need to get good answers.

Experimentation has been around for a long time. People have been testing out new ideas for far longer than data science has been a thing. But still, experimentation is at the heart of a lot of modern data work. Why has it had this modern explosion?
Essentially, the reason comes down to ease of opportunity.
Nowadays, almost any digital interaction is subject to experimentation. If you own a business, for example, you can split, test, and treat your entire user base in an instant. Whether you're trying to create a more compelling home page, or increase the probability your customers open emails you send them, everything is open to experiments. And on the flip side, though you may not have noticed, you have almost certainly already been a part of some company's experiment as they try to iterate towards a better business.
While setting up and executing these experiments has gotten easier, doing it right hasn't.
Data science is essential in this process. While setting up and executing these experiments has gotten easier, doing it right hasn't. Knowing how to run an effective experiment, keep the data clean, and analyze it when it comes in are all parts of the data scientist repertoire, and they can be hugely impactful on any business. Careless experimentation creates biases, leads to false conclusions, contradicts itself, and ultimately can lead to less clarity and insight rather than more.
Machine learning (or just ML) is probably the most hyped part of data science. It's what a lot of people conjure up when they think of data science and it's what many set out to learn when they try to enter this field. Data scientists define machine learning as the process of using machines (aka a computer) to better understand a process or system, and recreate, replicate or augment that system. In some cases, machines process data in order to develop some kind of understanding of the underlying system that generated it. In others, machines process data and develop new systems for understanding it. These methods are often based around that fancy buzzword “algorithms” we hear so much when folks talk about Google or Amazon. An algorithm is basically a collection of instructions for a computer to accomplish some specific task — it's commonly compared to a recipe. You can build a lot of different things with algorithms, and they'll all be able to accomplish slightly different tasks.
If that sounds vague, it's because there are many different kinds of machine learning that are grouped under this banner. In technical terms, the most common divisions are Supervised, Unsupervised, and Reinforcement Learning.

Supervised learning is probably the most well known of the branches of data science, and it's what a lot of people mean when they talk about ML. This is all about predicting something you’ve seen before. You try to analyze what the outcome of the process was in the past and build a system that tries to draw out what matters and build predictions for the next time it happens.
This can be a really useful thing to do, for everything. From predicting who is going to win the Oscars to what ad you're most likely to click on to whether or not you're going to vote in the next election, supervised learning can help answer all of these questions. It works because we've seen these things before. We've watched the Oscars and can find out what makes a film likely to win. We've seen ads and can figure out what makes someone likely to click. We've had elections and can determine what makes someone likely to vote.
Before machine learning was developed, people may have tried to do some of these predictions manually, say looking at the number of Oscar nominations a film receives and picking the one with the most to win. What machine learning allows us to do is operate at a much larger scale and pick out much better predictors, or features, to build our model on. This leads to more accurate prediction, built on more subtle indicators for what is likely to happen.

It turns out you can do a lot of machine learning work without an observed outcome or target. This type of machine learning, called unsupervised learning is less concerned about making predictions than understanding and identifying relationships or associations that might exist within the data.
One common unsupervised learning technique is the K Means algorithm. This technique, calculates the distance between different points of data and groups similar data together. The “suggested new friends” feature on Facebook is an example of this in action. First, Facebook calculates the distance between users as measured by the number of “friends” those users have in common. The more mutual friends between two users, the “closer” the distance between two users. After calculating those distances, patterns emerge and users with similar sets of mutual friends are grouped together in a process called clustering. If you ever received a notification from Facebook that looks like this…


chances are you are in the same cluster.
While supervised and unsupervised learning answer have different objectives, it's worth noting that in real world situations, they often take place simultaneously. The most notable example of this is Netflix. Netflix uses an algorithm often referred to as a recommender system to suggest new content to its viewers. If the algorithm could talk, it's supervised learning half would say something like “you'll probably like these movies because other people that have watched these movies liked them”. Its unsupervised learning half would say “these are movies that we think are similar to other movies that you've enjoyed”.
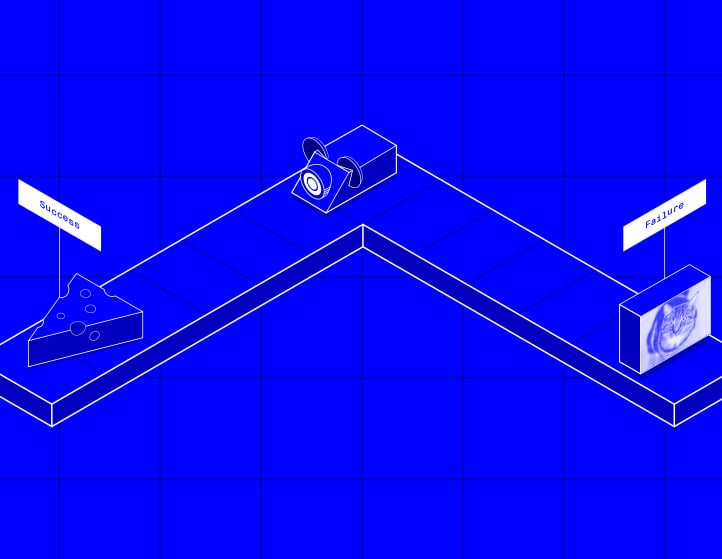
Depending on who you talk with, reinforcement learning is either a key branch of machine learning or something not worth mentioning at all. In any case, what differentiates reinforcement learning from its machine learning brethren is the need for an active feedback loop. Whereas supervised and unsupervised learning can rely on static data (a database for example) and return static results (the results won't change because the data won't), reinforcement learning requires a dynamic dataset that interacts with the real world. For example, think about how small kids explore the world. They might touch something hot, receive negative feedback (a burn) and eventually (hopefully) learn not to do it again. In reinforcement learning, machines learn and build models the same way.
There have been many examples of reinforcement learning in action over the past 25 years. One of the earliest and best known was Deep Blue, a chess playing computer created by IBM. Using reinforcement learning (understanding what moves were good and which were bad) Deep Blue would play games, getting better and better after each opponent. It soon became a formidable force within the chess community and in 1996, famously defeated chess grand Champion Garry Kasparov.

Artificial intelligence is a buzzword that might be just as buzzy as data science (or even a tad more). The difference between data science and artificial intelligence can be somewhat vague, and there is indeed a lot of overlap in the tools used.
Inherently, artificial intelligence wants some kind of human interaction and is intended to be somewhat human or “intelligent” in the way it carries out those interactions. Therefore, that interaction becomes a fundamental part of the product a person seeks to build. Data science is more about insight and building systems. It places less emphasis on human interaction and more on providing intelligence, recommendations, or insights.

Whether you work in medicine, media, finance, or manufacturing, data science will likely play a big role moving forward. Just think about it:
Every field has big questions.
Every field has big sets of data.
So every field needs data scientists!
If you feel excited about data science, now is a perfect time to start exploring. Stats suggest that data science skills are in high demand and making the career transition can happen in as little as 6 months. Granted those will probably be the 6 toughest months of your life, but in the end, and trust us on this one, it will be worth it. Data scientists are some of America’s best paid and happiest workers. To quote famous data scientist Dr. Kirk Borne:
As a successful data scientist, your day can begin and end with you counting your blessings that you are living your dream by solving real-world problems with data.
Is now the time for you to live your dream too?
Learn more about how you can become a data scientist by exploring Thinkful's data science bootcamp.